[프로젝트] Dacon 인공지능 챌린지 참여 후기
-> 8월 15일부터 8월 20일까지 Dacon 인공지능 챌린지에 참여하였다. 지금까지는 딥러닝을 이론으로만 배웠었는데, 이렇게 실제로 딥러닝을 적용해보니 많은 것들을 배울 수 있었다. 그러나 많이 배웠다는 것은 그 만큼 많은 시행착오를 거쳤다는 것! 내가 배운 것과 닥쳤던 어려움들과 해결방법들을 정리해서 포스팅하고자 한다.
https://www.dacon.io/competitions/official/235750/overview/description
2021 인하 인공지능 챌린지 - DACON
2021 인하 인공지능 챌린지 [주제] 안면 인식 기반 신원 검증 (face verification) [대회 설명] 안면 인식 인공지능을 기반으로 한 생체 인식 기술 중 하나로서 주어진 얼굴 영상과 데이터베이스에 저장
www.dacon.io

1. 대용량 데이터 압축 해제에 막혔다.
데이콘에서 제공해준 압축된 파일은 로컬 컴퓨터에 풀어야 했다. 파일은 크게 train용 데이터와 test용 데이터로 구분이 되어 있었는데, train용 데이터의 용량이 거의 13GB로 대규모 용량이었다. 이 데이터를 로컬 컴퓨터에 풀기 위해 기존에 사용하고 있던 알집과 반디집을 이용해서 압축을 풀려고 했으나 번번히 실패하였다.

GPU를 사용하면 쉽게 풀 수 있을 것 같아 Google Colab을 이용하여 Google Drive에 압축 파일을 풀었다.
python 라이브러리인 ZipFile을 이용해서 풀었다 zipFile 이용법은 아래 링크를 참고하면 좋을 것 같다.(근데 시간이 오래 걸리긴 하였음)
https://yganalyst.github.io/data_handling/memo_2/
[Python] zipfile 모듈, 압축파일 다루기
zipfile 모듈을 활용해서 압축 파일을 다루는 방법을 알아보자
yganalyst.github.io
하지만 뒤에 데이터 전처리 과정이 문제였다. 파일의 총 개수가 300만개였고, 이 파일을 다 읽는데만 해도 시간이 너무 오래 걸려 런타임 오류가 발생하였다.
결론은 압축 푸는 프로그램 중 하나인 7zip을 이용하였다. 다른 압축 파일 프로그램(알집, 반디집)들과 비교했을 때 훨씬 빠르고 안전하게 압축을 해제할 수 있었다.
해결책 : 7zip으로 local 컴퓨터에 압축 해제!
2. 압축 해제 과정 중 디스크 내 용량의 급발진
7zip을 이용하여 E드라이브에 파일들을 압축해제하려고 했다. 그런데 갑자기 오류가 발생하였다. 분명 용량은 5GB인데, 디스크 내 용량이 500GB로 거의 100배 이상을 차지한 것이었다.
다른 파일들은 용량과 디스크 내 용량이 비슷하던데, 내가 푸는 압축파일만 이상했다.

찾아보니, 내가 압축을 풀었던 E드라이브는 파일 시스템이 exFAT이었다.
exFAT은 usb같은 디바이스 용이었고, 압축 파일을 풀기 위해선 ntfs 파일시스템인 드라이브에 풀어야 하는 것 같다. ntfs시스템인 D드라이브에 압축 해제하였더니 아무 탈 없이 압축을 풀 수 있었다.
자세한 내용은 아래 링크들을 참고하면 좋을 것 같다.
https://m.blog.naver.com/myrikason/221353874580
USB 포맷 NTFS, FAT32, exFAT의 차이점 간단 정리
2021.02.07 본문에 미흡한 내용에 대해 'Korkic'님께서 댓글로 추가해주신 내용을 상위에 남겨...
blog.naver.com
http://m.todayhumor.co.kr/view.php?table=total&no=10856835
하드디스크 내 용량 문제, 이거 왜 이러는 건가요?
얼마 전 2TB 외장하드디스크를 구입해서 exFAT로 할당 단위 크기를 16,384 kilobytes로 설정한 후 포맷을 했습니다. 그런 후 파일들을 외장하드디스크에 넣으니
m.todayhumor.co.kr
어떤 파일 시스템을 선택하느냐에 따라서 그 저장 장치의 속성이 달라진다!!
해결책 : 드라이브 파일 시스템이 ntfs인 D드라이브에 압축 파일 해제!
3. Github 함수 사용
논문이나 프로젝트에서 구현한 모델들은 대부분 .py형태의 파일로 깃허브에 올라간다. 딥러닝을 공부할 때 원래 jupyter notebook만을 사용했어서 .py 파일들이 낯설었고, 어떻게 이용하는지도 잘 몰랐다.
우선 깃허브에 있는 모델들을 사용해야 했기 때문에 clone하여 pycharm으로 파일을 열었다. 그러자 파이썬 파일에 주석처리된 부분이 보이면서 어떻게 파일을 사용해야 하는지가 설명되어 있었다.
약간 관련 없어 보일 수 있지만 tensorflow에서 쓰는 fit( )나 compile( )들도 다 일종의 함수라는 것을 깨달았다.
다만 parser부분은 아직 공부가 필요한 듯 하다. 여튼 딥러닝 학습에 모델을 사용할 수 있었다.
4. No module name 'A', Kernel 연결로 해결
anaconda prompt에서 conda install 명령어를 통해 A라는 라이브러리를 설치하였다. 뿐만 아니라 conda list를 했을 때도 그 라이브러리가 있다는 것을 확인까지 했다.
가상환경을 만들고 그 가상환경에서 jupyter notebook을 실행시키고 import A를 하니 no module name 'A'라는 오류가 발생하였다.
이는 커널을 연결해주지 않았기 때문에 발생하는 오류였다. 자세한 내용은 아래 링크를 참고하면 될 것 같다.
https://chancoding.tistory.com/86
Jupyter Notebook에 가상환경 Kernel 연결하기
목차 1. 아나콘다 가상 환경 만들기 아나콘다에 가상환경을 구성하도록 합니다. tf2.0 이라는 이름을 가진 파이썬 가상 환경을 만들었습니다. conda create -n tf2.0 python 자세한 내용은 이전 글을 통해
chancoding.tistory.com
해결책 : 가상환경 Kernel을 연결해준다.
5. GPU를 사용하기 위한 고군분투
5-1. GPU 사용
1) GPU를 사용하기 위해 tensorflow-GPU설치
왜인지 모르겠지만 경로가 꼬여 tensorflow의 여러 라이브러리들이 인식되지 않았다. 그래서 anaconda를 밀고 다시 설치하였다.
2) CUDA 버전, NVIDIA 버전 일일히 맞추어 주었다.
결국 이렇게 해도 GPU를 사용할 수 없어 colab의 GPU를 이용하였다.
5-2. Colab GPU 사용
1) 맨 처음 colab을 사용할 때의 문제점인 "데이터 전처리 과정에서 세션이 종료"됨은 batch size를 나누어 줌으로써 해결할 수 있었다.
압축 파일을 한꺼번에 푸는 것이 아니라 batch size를 나누어 풀었고, 전처리 과정 또한 300만개의 데이터들을 10만개 씩 끊어서 전처리하였다.
+) 이 과정에서 2가지를 배웠다.
(1) python library 중 tqdm을 이용하면 처리 과정을 실시간으로 알 수 있다.
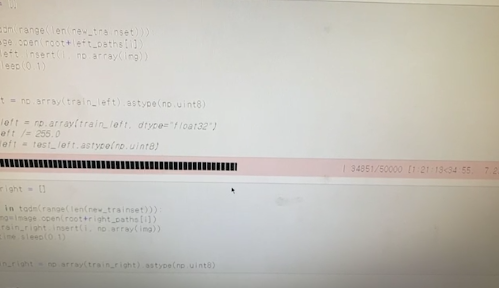
(2) for 문 오류
for 문으로 데이터들을 어느 배열에 넣을 때 list index out of range라는 오류가 발생한다.
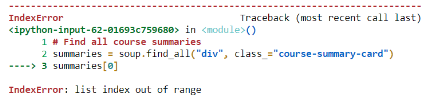
이럴 때는 우선 크기 비교를 해주고, 크기 비교를 했을 때 별 문제 없다면 셀 실행을 취소하고 처음부터 실행하면 된다.
2) 하지만 Colab의 또 다른 문제점에 봉착했다.
- 세션 끊김 문제
이는 아래 링크를 통해 개발자 모드에서 아래 소스코드를 입력함으로써 해결하였다.
구글 코랩 (Google colab)의 런타임 연결 끊김을 방지하는 방법
구글 코랩 (Google colab)의 런타임 연결 끊김을 방지하는 방법에 대한 내용입니다.
teddylee777.github.io
개발자 모드(F12)를 누르고, console창에 들어가 아래 소스코드를 그대로 복붙하여 입력하면 된다.
function ClickConnect(){
console.log("코랩 연결 끊김 방지");
document.querySelector("colab-toolbar-button#connect").click()
}
setInterval(ClickConnect, 60 * 1000)
- Colab에 설치했거나 압축 해제했던 파일들이 없어져있다.
코랩은 12시간이 지나면 무조건 세션이 종료되는데, 이 때 압축 해제하거나 생성한 파일들은 전부 초기화된다.
따라서 세션이 종료되면 다시 해줘야 한다!!!!
위의 두 문제는 해결할 수 있었지만 아래의 오류들은 해결할 수 없었다.
- GPU 벡엔드 사용 불가 알림 메시지

- 메모리 다 사용
Colab은 기본적으로 약 12GB의 램을 제공한다. 하지만 이 대회의 데이터를 다루기에는 턱없이 부족한 용량이었다....
결국 Colab Pro를 구입하였다.
5-3. Colab-Pro GPU 사용

확실히 성능도 좋아졌을 뿐만 아니라 용량도 100GB 이용할 수 있다.
한달에 9.99달러로, 약 12000원만 지불하면 된다.
일반 colab보다 성능이 좋지만 연구실 내 GPU를 활용하는 것이 훨씬 효율적일 것 같다.
결론
대회는 실패했지만 많은 것들을 배우고 얻을 수 있었다. 위에 작성한 것 외에도 cosine 유사도 등 여러 것들을 얻을 수 있었다. 전보다 딥러닝이랑도 더 친해진 것 같다.
진짜 거의 무박 5일(?)의 일정이라 약간 힘들기도 했지만 연구실 분들도 너무 잘 챙겨주셨고, 또 재밌기도 해서 힘들기만 한 여정은 아니었다!