

▶ 컨볼루션 신경망 (Convolutional Neural Network)의 목적성
DNN (Deep Neural Network)는 주로 1차원 형태의 데이터를 사용한다. 따라서 그림이나 이미지와 같은 2차원 형태의 데이터를 사용할 때는 1차원 형태로 flatten시켜야 한다. (완전 연결 계층, fully connected layer)
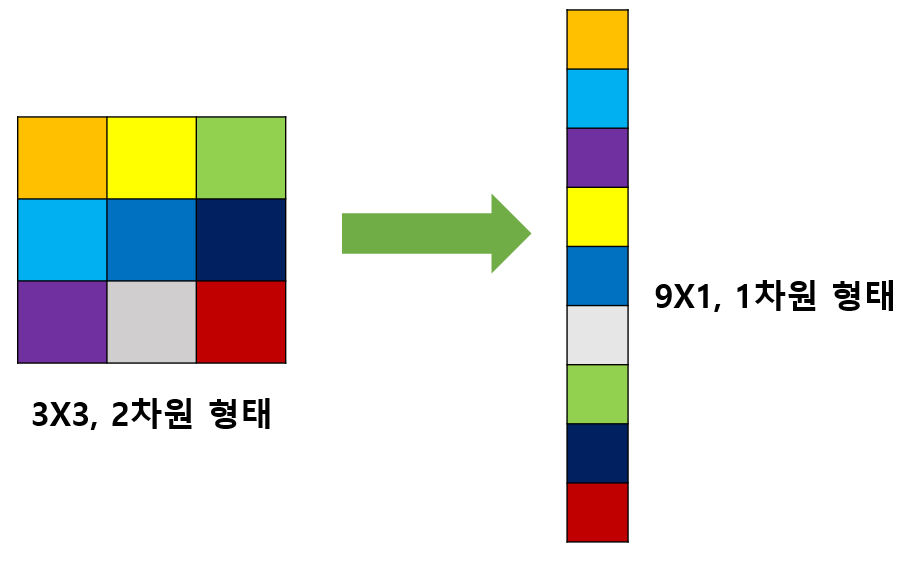
flatten을 시키는 완전 연결 계층은 크게 2가지의 문제점이 발생한다.
1. 이는 데이터의 형상을 완전히 무시하게 된다.
2. 추상화 과정 없이 바로 연산과정에 넘어가버리므로 학습시간과 능률 측면에서 효율성이 떨어진다.
CNN은 이러한 문제점을 해결하기 위해 도입된 방법이다. CNN은 완전 연결 계층과 달리 2차원 형태의 배열을 그대로 사용할 수 있다.
▶ 이미지의 컨볼루션을 이용한 필터링
(0) 이미지 분석

CNN은 특성상, 음성이나 이미지에서의 특징 추출에서 적극적으로 활용이 된다. 이는 '커널 (Kernel)'이라는 필터를 이용하기 때문인데, 직접 CNN을 이용하여 이미지를 필터링 하여 보자.

위와 같이 2차원 평면에 그림이 있다. 이제 이를 CNN모델을 이용하여 특징을 추출해보자.
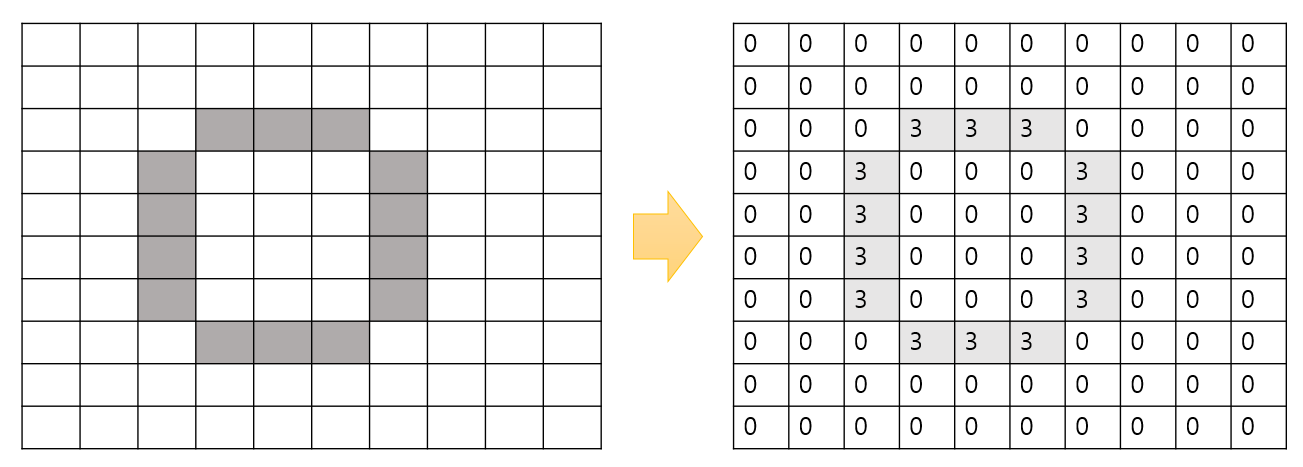
단순히 이미지를 이용하여 특징 추출은 불가능하기 때문에 이를 데이터로 바꾸어준다. 이를 픽셀 (Pixel)이라고 부르는데, 원본 이미지의 각 픽셀은 입력변수 또는 특성이 된다. 색깔이 있는 부분은 0으로, 색깔이 회색인 부분은 3으로 표시를 하였다.
필터 커널
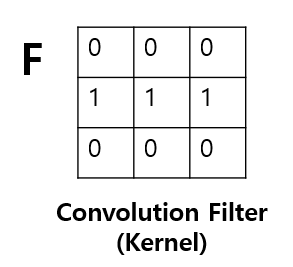
이제 이 필터커널이라는 필터를 이용하여 이미지를 필터링을 한다.
필터 커널을 사용해 원본 이미지에 컨볼루션을 취하면 필터의 특성에 맞게 강조된 이미지를 얻을 수 있다. 따라서 필터 커널에 있는 값들은 사용자가 임의로 지정하는 것이다. 필자는 위의 그림과 같이 필터의 값들을 설정하였다.
보폭 Stride
필터링은 필터를 이미지에 놓고 움직이면서 한다. 이때 필터가 한번에 움직이는 거리를 보폭, 흔히 스트라이드라고 부른다. 필터 커널이 한 칸씩 움직이면 스트라이드 값은 1이 되고, 두 칸씩 움직이면 2가 된다.
예를 들어 원본 이미지의 크기가 m x m이고, 필터 커널의 크기가 n x n, 스트라이드의 크기를 s라고 하면, 필터링을 통해 얻은 이미지는 (m-n)/s+1 x (m-n)/s+1의 크기가 된다.
(1) 필터링 Filtering, 합성곱, Conv

이제 필터링을 해볼 것이다. 아래 그림에서 필터링이 원본 이미지 픽셀에 색칠되어 있는 부분을 필터링 하자고 하자.
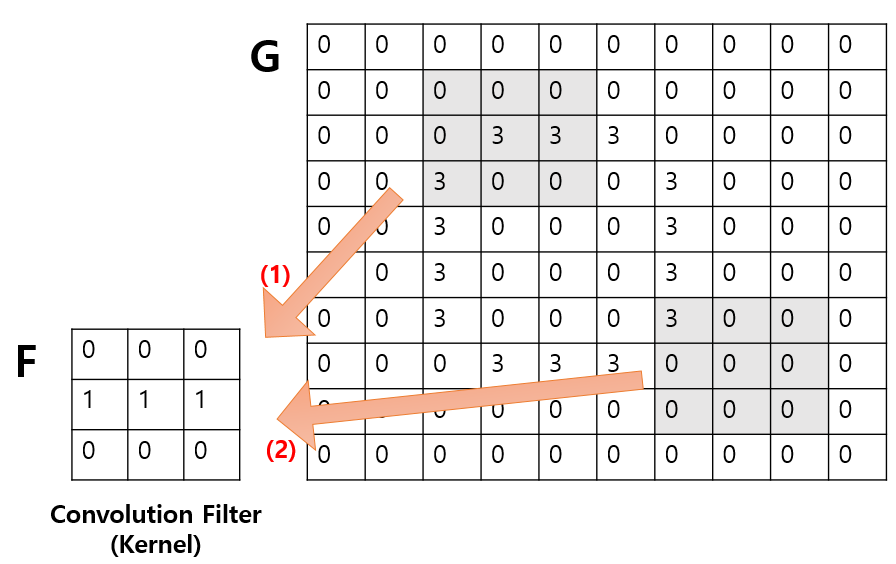
필터링 결과, 아래와 같이 나온다.

이처럼, 커널 필터를 움직이면서 위와 같이 계산을 해주면 필터링이 끝난다. 이렇게 필터링 하여 생성된 지도를 특성 지도 (Feature Map)이라고 한다.
가중치 공유
위의 과정을 보면, 필터 커널인 F의 성분 값들은 고정이 되어 있다. 즉, 동일한 한 가지의 필터를 가지고 전체 입력 데이터(원본 이미지의 픽셀값)에 동일하게 적용한다. 이를 가중치 공유(Shared Weight)라고 하는데, 이를 통해 매개변수가 감소해 역전파 계산시 문제의 복잡도가 상당한 크기로 줄어든다.
패딩(Padding)
위와 같이 필터링을 하게 되면 결과적으로 8x8 크기의 특성지도가 나온다. 하지만 만약 필터커널의 크기가 더 크거나 Stride 값이 더 크다면 특성지도의 크기는 더 작아질 것이다. 따라서 이로 인해 출력 데이터가 줄어들게 되어 데이터 손실이 발생할 수 있다. 이러한 문제점을 해결하기 위하여 패딩(Padding)이라는 개념을 도입하였다.
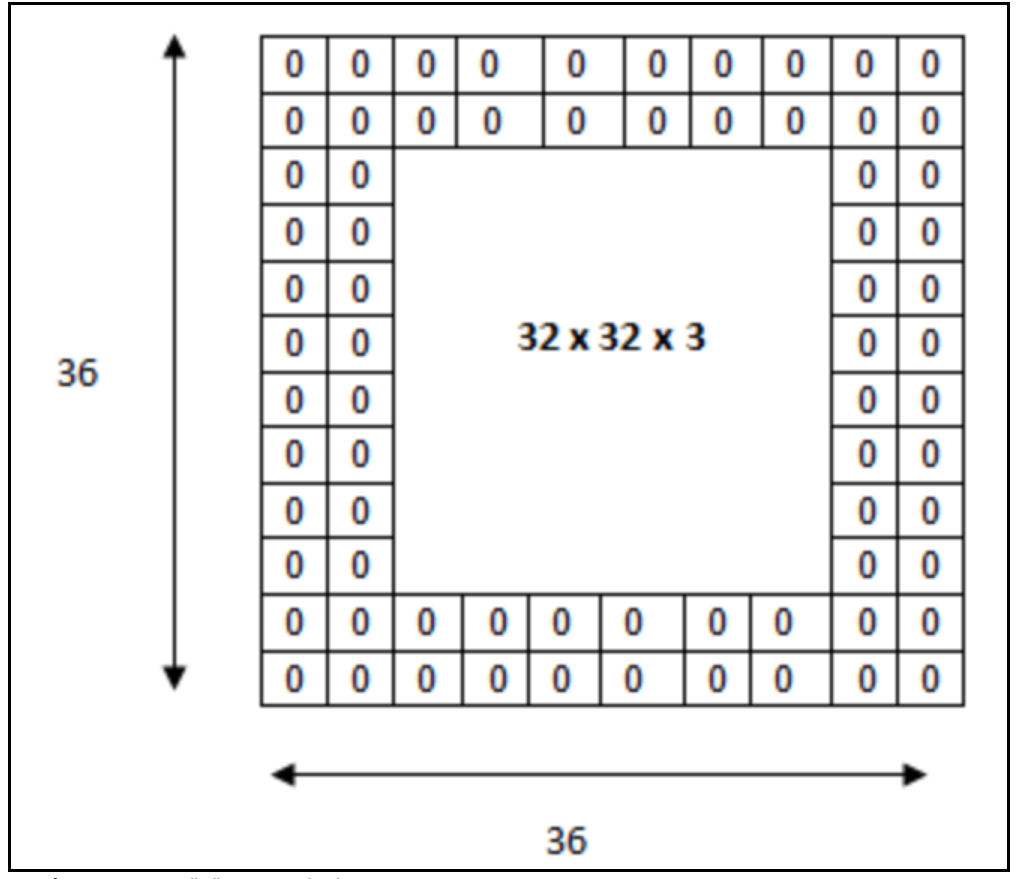
위의 그림과 같이 입력 데이터의 외각을 특정한 값으로 패딩한다. 보통 패딩 값으로는 0을 주로 사용한다.
이미지의 가장자리에 특정값으로 설정된 픽셀들을 추가함으로써 입력 이미지와 출력이미지의 크기를 같거나 비슷하게 만드는 역할을 수행한다.
(2) 활성화 함수 통과

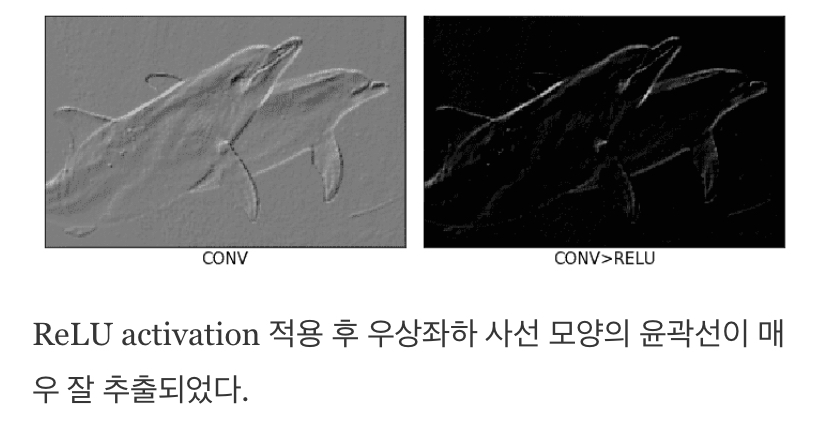
필터 커널을 이용해 Convolution 계산이 완료되면 특성 지도의 각 픽셀에 있는 데이터를 활성화 함수에 적용해 좀 더 판별력 있게 만든다. 여러 활성화 함수 중, ReLU함수를 많이 사용이 되는데, 이를 이용해 입력데이터를 적절히 활성화까지 하면 필터링 과정이 완료된다.
(3) 풀링
예로 들었던 원본 이미지는 10x10 의 크기, 필터커널은 3x3의 크기를 가진다. Stride 값을 1로 지정하여 주었다면 특성지도는 8x8의 크기를 갖게 된다. 필터링을 통해 데이터 이미지의 특성은 추출할 수 있었지만 처리해야 하는 데이터의 양은 크게 줄지 않는다. 이 때 풀링(Pooling)이라는 과정을 적용한다. 풀링은 2차원 데이터의 세로 및 가로 방향의 공간을 줄이는 연산이다. 풀링은 크게 최대풀링, 평균 풀링, 확률적 풀링이 있다.
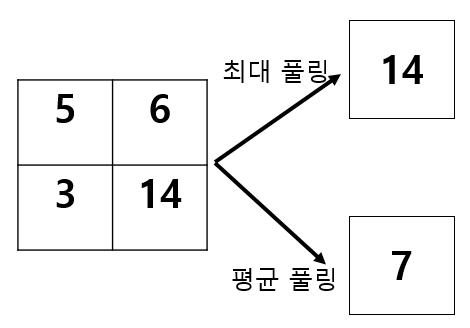
필터커널의 크기는 3x3이라고 하였다. 최대 풀링은 3x3 크기 내에 있는 Convolution 데이터에서 가장 큰 것을 대푯값으로 취하는 것인데, 직관적이고 계산의 편리성이 있지만 최대로 선택된 값이 노이즈인 경우 오버피팅을 유발할 수 있다.
평균 풀링은 3x3 크기 내에 있는 데이터의 값의 평균을 취하는 방법으로 직관적이고 간편하지만 낮게 활성화된 성분값이 평균에 포함되면서 풀링 결과의 대비율을 떨어뜨릴 수 있다.
확률적 풀링은 최대풀링과 평균 풀링의 단점을 해결하기 위해 도입한 방법이다. 필터링된 데이터를 임의의 확률로 한개를 선정하여 풀링 크기 내에 모든 값을 고려할 수 있다는 가능성을 가진다는 장점을 가지고 있다.
(4) 마무리

이렇게 필터링, 활성화, 풀링의 과정을 거쳤다면 이를 반복한다. 마지막 풀링 과정을 거쳤다면 3x3 필터커널 크기의 10개의 데이터가 남게 된다. 이 데이터에 3x3 크기의 최종 필터 커널로 계산하게 되면 1x1, 즉 1차원 벡터 형태로 정렬이 되고, 각 뉴런의 입력값으로 저장된다.
채널
CNN에는 채널이 존재한다. Convolution Layer에 유입되는 입력 데이터에는 한 개 이상의 필터가 적용된다. 1개 필터는 Feature Map의 채널이 되므로, Convolution Layer에 n개의 필터가 적용된다면 출력 데이터는 n개의 채널을 갖게 된다. 지금까지의 과정이 바로 여러 채널 중 하나의 채널에 대하여 이루어진 현상이다.
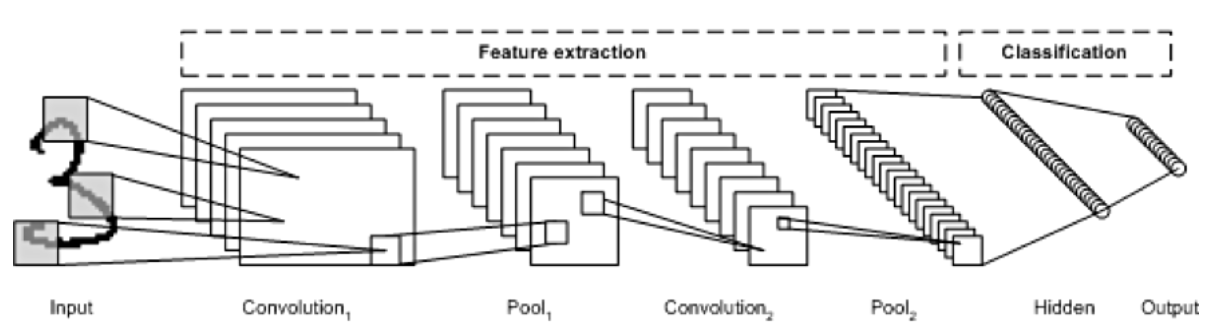
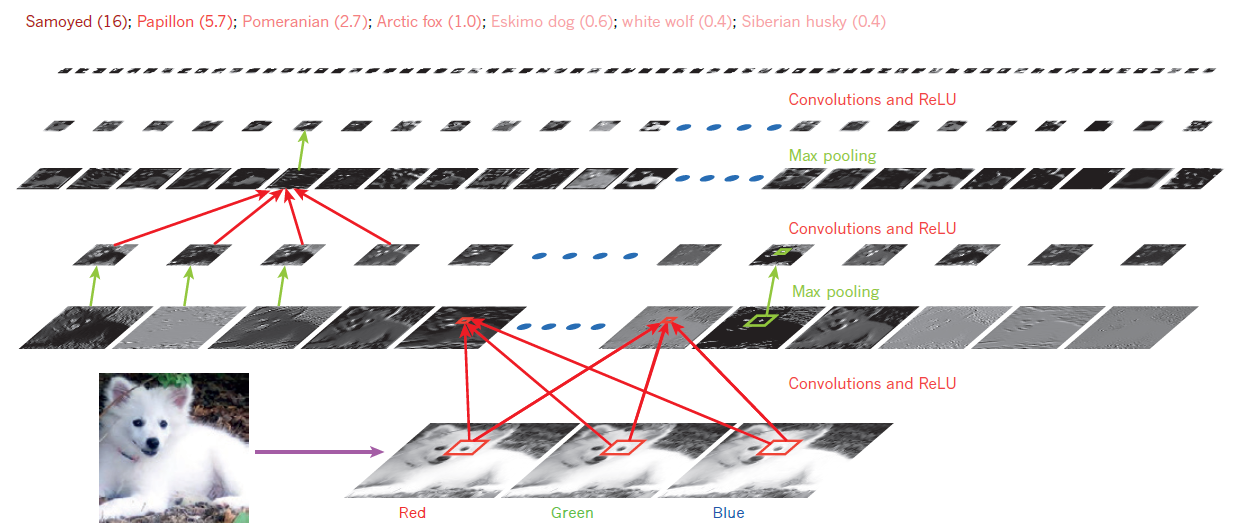
(5) 인식
Convolution과 풀링의 반복으로 이미지가 1차원 벡터 형태의 특성으로 압축된다. 이렇게 생성된 1차원 벡터의 특성 지도를 다른 특성 지도와 비교하여 이미지를 인식한다.
예를 들어, 가상으로 강아지의 최종 특성 지도가 [1,3,1,0,0,0,0,0,0,0]이라고 가정하자.
같은 방법으로 고양이와 오리에 대한 특성지도를 완성했다고 할 때, 다음과 같이 나타낼 수 있다.
고양이 : [16,12,15,11,0,0,0,0,0,0]
오리 : [0,0,0,0,0,0,3,4,2]
각 이미지마다 특성지도를 비교해보면 강아지와 고양이는 대체로 같은 위치에 크기가 다른 특성값이 저장되어 있음을 알 수 있다. 강아지와 고양이는 생김새가 비슷하기 대문에 특성지도에서 같은 위치에 특성값이 분포하고, 미세한 차이점은 각 성분값의 크기로 구별되는 것이다.
'🖥️ 컴퓨터공학 🖥️ > 머신러닝, 딥러닝' 카테고리의 다른 글
| [tar] 압축파일 linux로 바로 다운받기 (0) | 2023.01.19 |
|---|---|
| [ 딥러닝 알아가기 ] Transfer Learning과 Fine Tuning (2) | 2021.08.08 |
| [ 딥러닝 알아가기 ] 역전파(backpropagation) 제대로 이해하기 (0) | 2020.12.24 |
| [ 딥러닝 알아가기 ] 경사하강법, 역전파, SoftMax 함수 (0) | 2020.12.24 |
| [ tensorflow ] 간단한 선형회귀모델 만들기 (0) | 2020.12.21 |